Build H2O models with the FPGA backend
The purpose of this tutorial is to demonstrate the easiness of accelerating a Machine Learning application using FPGAs on H2O-3. A user that is comfortable with the H2O framework and features can continue using it seamlessly without knowing how the FPGA accelerated libraries are integrated in the familiar API.
Introduction-
H2O is an open-source, in-memory, distributed, fast, and scalable machine learning & predictive analytics platform that allows you to build ML models on big data and provides easy productionalization of those models in an enterprise environment. H2O’s core code is written in Java. Inside H2O, a distributed Key/Value store is used to access and reference data, models, objects, etc., across all nodes and machines.
H2O’s REST API allows access to all the capabilities of H2O from an external program or script via JSON over HTTP. The Rest API is used by H2O’s web interface (Flow UI), R binding (H2O-R), and Python binding (H2O-Python).
InAccel's integration with H2O is the first effort for an FPGA backend on this distributed framework, while the existing solutions for fast and efficient machine learning models include mainly GPUs, like H2O4GPU.
Requirements-
-
Operating System:
-
Ubuntu 12.04 or later
-
RHEL/CentOS 6 or later
-
-
Programming Language: No matter which language will be used for development (Python in our case), Java 7 or later is needed to run H2O and can be installed from the Java Downloads page.
-
Other: A Web browser is required to use H2O’s web UI, Flow.
Installation Steps-
This section will walk you through the installation of InAccel + H2O.
1. Get InAccel-
InAccel is an open platform for developing, shipping, and running accelerated applications. InAccel enables you to separate your applications from your accelerators so you can deliver high-performance software quickly.
You can setup InAccel toolset on any Linux platform and enable FPGA accelerator orchestration with a free license issued by InAccel, using this link.
2. Install InAccel - H2O Python package-
API walkthrough-
Now, we are going to explore the capabilities of the H2O framework with a simple machine learning example inside a common Jupyter Notebook.
First of all, we need to fetch the available accelerators from InAccel Store.
Import the h2o package, the algorithm class (H2OXGBoostEstimator) and initialize a new single node cluster.
Let's load and prepare the data using the H2O library utilities. The training set consists of 65k images while the rest 35k are used for validation purposes.
You will find more information about this dataset (SVHN) in the previous Tutorial Lab.
images = h2o.import_file('svhn.gz')
train, valid = images.split_frame(ratios = [0.65])
response = 'class'
train[response] = train[response].asfactor()
valid[response] = valid[response].asfactor()
predictors = images.columns[:-1]
After the data preparation stage, we can build a new XGboost model defining a set of learning parameters. You will notice that the only addition to the native XGBoost parameter list is the tree_method, which is now modified for FPGA-accelerated execution without extra code changes.
Changing the tree_method param from exact to fpga_exact and retraining the model, you will achieve more than 5x speed-up compared to an 8-threaded Intel Xeon CPU execution, without compromising the classification or regression outcome.
Find more about InAccel XGBoost project here.
params = {
'col_sample_rate_per_tree' : 0.9,
'learn_rate' : 0.2,
'max_depth' : 15,
'ntrees' : 10,
'tree_method' : 'fpga_exact'
}
model = H2OXGBoostEstimator(**params)
model.train(x = predictors, y = response, training_frame = train, validation_frame = valid)
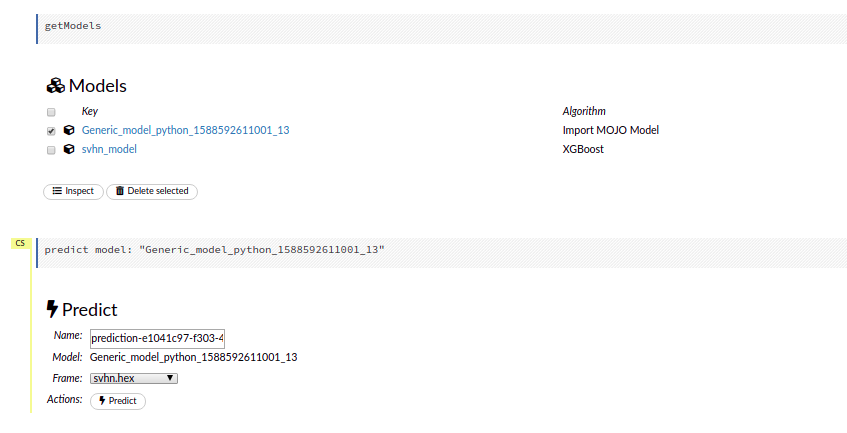
The model can be saved as a MOJO object in order to be easily loaded for use in production.
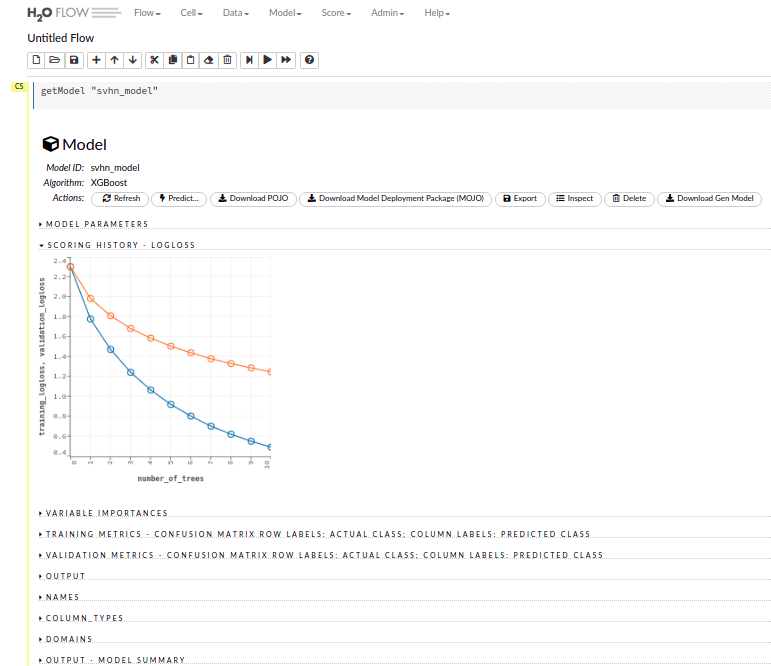
You may also want to access Flow Web UI which is usually running at http://localhost:54321 or in a different port that is announced during cluster initialization. There you can explore all model metrics, learning parameters and training/validation properties.
You can also import directly the saved model in the MOJO format and generate predictions for new frames of images.